အခန်း ၂ - Big-O, Time Complexity, Space Complexity
Algorithm ဘယ််လောက်ကောင်းသလဲဆိုတာကို စက္ကန့် နဲ့ မတိုင်းတာပါဘူး။ ဘာလို့လဲဆိုတော့ computer တစ်လုံး နဲ့ တစ်လုံးဟာ performance အမြန်နှုန်း မတူညီလို့ပါ။ ဒါကြောင့် အချက်အလက် ပမာဏ () များလာရင် algorithm က ဘယ်လောက်ထိ အလုပ်လုပ်ရမလဲ ဆိုတာကို သင်္ချာနည်းအရ Asymptotic Notations များ အသုံးပြုပြီး တိုင်းတာပါတယ်။
ဒီနေရာမှာ သဘောတရား နှစ်ခု ကို ခွဲမြင်ဖို့ အရေးကြီးပါတယ်။ ပထမက input အပေါ်မူတည်တဲ့ အခြေအနေ (Best / Average / Worst Case) ၊ ဒုတိယက growth rate bound ကို ဖော်ပြသည့် Notation (, , ) ပါ။
၁။ Input အခြေအနေ (Best / Average / Worst Case)
Algorithm တစ်ခုဟာ input ပေါ်မူတည်ပြီး အလုပ်လုပ်ရတဲ့ အကြိမ်အရေအတွက် ကွဲပြားနိုင်ပါတယ်။ ဒါကို အခြေအနေ (၃) မျိုး ခွဲပါတယ်။
- Best Case (အကောင်းဆုံး): ကံအကောင်းဆုံး input ။ ဥပမာ Linear Search နဲ့ Array
[5, 2, 9, 1, 7]ထဲက5ကို ရှာရင် ပထမဆုံးနေရာမှာပဲ ချက်ချင်းတွေ့ပါတယ်။ အကြိမ် ၁ ကြိမ်ပဲ လုပ်ရတယ်။ - Worst Case (အဆိုးဆုံး): ကံအဆိုးဆုံး input ။ အပေါ်က Array ထဲမှာ
10ကို ရှာရင် အကုန်ရှာပြီးမှ မတွေ့တာမျိုး ဖြစ်နိုင်ပါတယ်။ ကြိမ် လုပ်ရပါတယ်။ - Average Case (ပျမ်းမျှ): input အမျိုးမျိုးအတွက် ပျမ်းမျှ ကြာချိန်။ Linear Search အတွက် ပျမ်းမျှ ကြိမ်လောက် လုပ်ရပါတယ်။
Software Engineer တွေဟာ အဆိုးဆုံး အခြေအနေ (Worst Case) ကို ကြိုတင် မျှော်မှန်းထားရတဲ့အတွက် လက်တွေ့မှာ Worst Case ကို အဓိက သုံးကြပါတယ်။
၂။ Asymptotic Notations (, , )
ဒီ notation (၃) ခုက input အခြေအနေ မဟုတ်ပါဘူး။ growth rate ကို သင်္ချာနည်းအရ ချုပ်ဆို (bound) တဲ့ နည်းတွေ ဖြစ်ပါတယ်။ အခြေအနေ တစ်ခုခု (best / average / worst) ရဲ့ ကြာချိန်ကို ဒီ notation တွေနဲ့ ဖော်ပြလို့ ရပါတယ်။
Big O Notation - (Upper Bound)
ဒါကို Upper Bound လို့ ခေါ်ပါတယ်။ Algorithm တစ်ခုက အများဆုံး ဒီ growth rate ထက် မပိုနိုင်ဘူး ဆိုတဲ့ အပေါ်ဆုံး ကန့်သတ်ချက် ဖြစ်ပါတယ်။ ဥပမာ Linear Search ရဲ့ worst case ကို လို့ ဖော်ပြပါတယ်။
Big Omega Notation - (Lower Bound)
ဒါကို Lower Bound လို့ ခေါ်ပါတယ်။ Algorithm တစ်ခုက အနည်းဆုံး ဒီ growth rate တော့ ကြာမယ် ဆိုတဲ့ အောက်ဆုံး ကန့်သတ်ချက် ဖြစ်ပါတယ်။ ဥပမာ Linear Search ရဲ့ best case ကို လို့ ဖော်ပြပါတယ်။
Big Theta Notation - (Tight Bound)
upper bound နဲ့ lower bound နှစ်ခုလုံးက တူညီတဲ့အခါ notation ကို သုံးပါတယ်။
- ဥပမာ: Array
[5, 2, 9, 1, 7]ထဲက ဂဏန်း အားလုံးရဲ့ ပေါင်းလဒ် (Sum) ကို ရှာမယ်ဆိုရင် ကံကောင်းတာ၊ ကံဆိုးတာ မရှိဘဲ ဂဏန်း (၅) လုံးစလုံးကို အမြဲ ပတ်ရပါတယ်။ best case ရော worst case ရော ကြိမ် တူတူ ဖြစ်တဲ့အတွက် လို့ အတိအကျ ဆိုနိုင်ပါတယ်။
သတိ: (, ) တွေက bound တွေ ဖြစ်ပြီး၊ best/average/worst တွေက input အခြေအနေ ဖြစ်ပါတယ်။ သဘောတရား နှစ်မျိုး မတူပါဘူး။ ဒါပေမယ့် လက်တွေ့မှာ worst case ကို Big O () နဲ့ ဖော်ပြလေ့ ရှိတဲ့အတွက် developer အများစုက "Big O = worst case" လို့ အလွယ်တကူ မှတ်ထားကြတာ ဖြစ်ပါတယ်။
ဥပမာ
ရန်ကုန် ကနေ မန္တလေး ကို ကားမောင်းသွားတယ် ဆိုပါစို့။ (real world example မဟုတ် ပဲ conceptual example ပါ။)
- best-case runtime: လမ်းမှာ လုံးဝကားမပိတ်၊ ရာသီဥတုကကောင်း၊ အမြန်ဆုံး အရှိန်နဲ့ သွားမယ်ဆိုရင် အနည်းဆုံး (၈) နာရီ ကြာမယ်။ ဒီ အနိမ့်ဆုံး အချိန်ကို နဲ့ ဖော်ပြနိုင်ပါတယ်။
- worst-case runtime: လမ်းမှာ ကားပိတ်တာ၊ မိုးရွာတာ အဆိုးဆုံးကြုံရင်တောင် အဆိုးဆုံး အခြေအနေအဖြစ် (၁၁) နာရီခန့် ကြာနိုင်တယ်လို့ ယူဆပါစို့။ ဒီ အမြင့်ဆုံး အချိန်ကို နဲ့ ဖော်ပြနိုင်ပါတယ်။
- tight estimate: အနိမ့်ဆုံး နဲ့ အမြင့်ဆုံး အချိန်ဟာ တူနေတဲ့ အခါ (ဥပမာ ပုံမှန် မောင်းရင် အမြဲ (၉) နာရီခန့်) အတိအကျ ခန့်မှန်းနိုင်ပါတယ်။ ဒါကို နဲ့ ဖော်ပြနိုင်ပါတယ်။
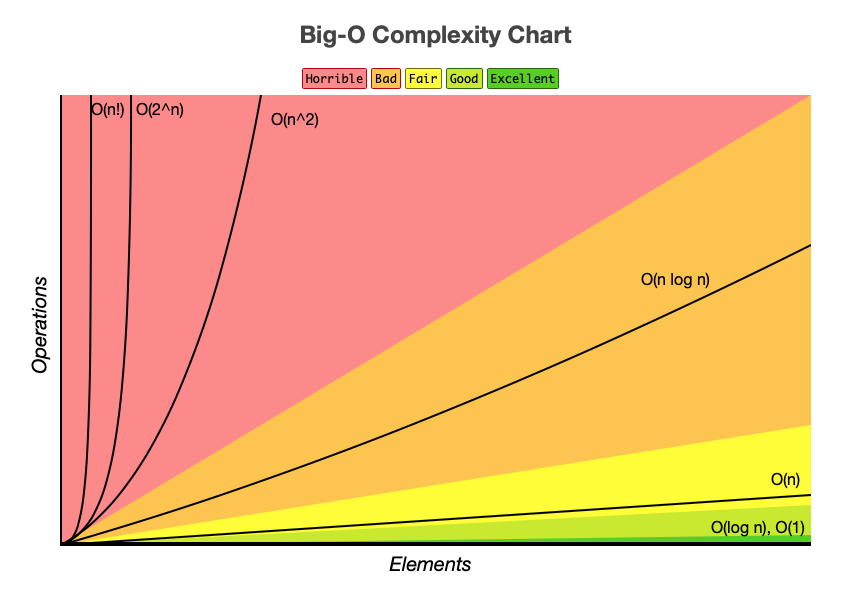
အသုံးများတဲ့ Big O အမျိုးအစားများ
Computer Science မှာ Big O ဟာ လက်တွေ့ အသုံးအများဆုံးပါ။ အမျိုးအစားတွေကတော့
- - Constant Time: Data ဘယ်လောက်များများ ကြာချိန် အတူတူပဲ။ ဥပမာ Array Index တစ်ခု ကို ယူတာ
- - Linear Time : Data များလေလေ အချိန်ကြာလေလေ။ ဥပမာ Array ထဲမှာ အခန်း အစ ကနေ အဆုံး ထိ ရှာဖွေခြင်း
- - Linearithmic Time: O(N) ထက် အနည်းငယ် ပိုကြာသော်လည်း ထက် အများကြီး ပိုမြန်တယ်။ ဥပမာ Merge Sort ကဲ့သို့သော Algorithm
- - Quadratic Time: input size တိုးလာတာနဲ့အမျှ ကြာချိန်က နှစ်ထပ်ကိန်းအချိုးနဲ့ တိုးလာတယ်။ အဆင့်ဆင့် loop ပတ်နေတာမျိုး
- - Logarithmic Time: Data များလာပေမယ့် ကြာချိန် အနည်းငယ်ပဲ တိုးလာခြင်း။ မြန်ဆန်သည့် စနစ်လို့ ဆိုနိုင်တယ်။
Big O တွက်ချက်ခြင်း
Big O Notation ကို တွက်ချက်သည့် အခါမှာ အဓိက Golden Rule ၃ ခု ရှိပါတယ်။
အဆင့်ဆင့် တွက်ချက်ခြင်း ဥပမာ
Algorithm ကို အဆင့်ဆင့် ဘယ်လို တွက်ချက်လဲဆိုတာ အောက်ပါ Java Code လေးနဲ့ အရင် လေ့လာကြည့်ရအောင်။
int sum = 0; // 1
int mul = 1; // 1
for (int i = 0; i < array.length; i++) { // N ကြိမ်
sum = sum + array[i]; // N ကြိမ်
mul = mul * array[i]; // N ကြိမ်
}
အပေါ်က code မှာ အစကိန်းသေ နှစ်ကြောင်းက ၁ ကြိမ်စီ အလုပ်လုပ်တယ်။ Loop က N ကြိမ် ပတ်တယ်။ Loop အထဲက ကုဒ်တွေကလည်း N ကြိမ်စီ အလုပ်လုပ်တယ်။
စုစုပေါင်းလုပ်ဆောင်ချက်ကို 1 + 1 + N + N + N = 2 + 3N ဆိုပြီး အကြမ်းဖျင်း ယူဆလို့ရပါတယ်။
Big O Notation ကို သတ်မှတ်တဲ့အခါ ဒီလို ကိန်းဂဏန်းတွေထဲကနေ အဓိက Golden Rule ၃ ခု ကို အသုံးပြုပါတယ်။
၁။ ကိန်းသေများကို ပယ်ဖျက်ပါ
အပေါ်က တွက်လဒ် 2 + 3N မှာ ကိန်းသေ (Constants) တွေဖြစ်တဲ့ အပေါင်း 2 နဲ့ အမြှောက် 3 ကို ပယ်ဖျက်ပါတယ်။ ဒါကြောင့် အကျဉ်းချုံးလိုက်ရင် လို့ပဲ သတ်မှတ်ပါတယ်။ Algorithm တစ်ခုက သို့မဟုတ် အဆင့်တွေ ယူတယ်ဆိုရင်လည်း ကိန်းသေ တွေကို ပယ်ဖျက်ပြီး လို့ပဲ သတ်မှတ်ပါတယ်။ အချက်အလက် ဘယ်လောက် ပွားလာလဲ ဆိုသည့် အချိုးအဆ ကို ပဲ အဓိက ထားလို့ပါ။
၂။ အဓိက မကျသည့် ကိန်းများကို ပယ်ဖျက်ပါ
Algorithm ရဲ့ ကြာချိန်က တွက်လိုက်လို့ ဖြစ်နေခဲ့လျှင် က ထက် အများကြီး ပိုမြန်မြန် ကြီးထွားလာနိုင်သည့် အတွက် အရေးမပါတဲ့ ကို ပယ်ဖျက်ပြီး လို့ ပဲ ယူပါတယ်။
public void printNumbers(int[] array) {
for (int i = 0; i < array.length; i++) { // O(N)
System.out.println(array[i]);
}
for (int i = 0; i < array.length; i++) { // O(N^2)
for (int j = 0; j < array.length; j++) {
System.out.println(array[i] + array[j]);
}
}
}
အပေါ်က ဥပမာမှာ ပထမ Loop က ကြာပြီး၊ ဒုတိယ Loop အထပ်က ကြာပါတယ်။ စုစုပေါင်း Time Complexity က ဖြစ်ပေမယ့်၊ ဟာ တဖြည်းဖြည်း အရေးမပါတော့တဲ့အတွက် ပယ်ဖျက်လိုက်ပြီး လို့ပဲ သတ်မှတ်ပါတယ်။
၃။ ပေါင်းခြင်း နှင့် မြှောက်ခြင်း
အဆင့် လုပ်ပြီးမှ အဆင့် ကို ဆက်လုပ်တယ်။ အဲဒီလို case ဆိုရင် ပေါင်းပါတယ်။
for (int i = 0; i < arrayA.length; i++) { // O(A)
System.out.println(arrayA[i]);
}
for (int j = 0; j < arrayB.length; j++) { // O(B)
System.out.println(arrayB[j]);
}
// Time Complexity: O(A + B)
အဆင့် တစ်ခါလုပ်တိုင်း အဆင့် ကို ထပ်ခါ ထပ်ခါ လုပ်ရတယ်။ ဥပမာ Nested Loop လိုမျိုး ဆိုရင် မြှောက်ပါတယ်။
for (int i = 0; i < arrayA.length; i++) { // O(A)
for (int j = 0; j < arrayB.length; j++) { // O(B)
System.out.println(arrayA[i] + arrayB[j]);
}
}
// Time Complexity: O(A * B)
Time Complexity
Time Complexity ဆိုတာ အချက်အလက် ပမာဏ အပေါ်မှာ မူတည်ပြီး Algorithm အလုပ်လုပ်ရသည့် အကြိမ်အရေ အတွက် ဘယ်လောက် များလဲဆိုတာ တိုင်းတာခြင်း ဖြစ်ပါတယ်။
Constant Time
အချက်အလက် ဘယ်လောက်ပဲများများ အလုပ်လုပ်ရသည့် အချိန် အတူတူပါပဲ။
public void printFirstElement(int[] array) {
// Array ထဲမှာ ဂဏန်း ၁၀ လုံးပဲရှိရှိ၊ သန်း ၁၀ဝ ပဲရှိရှိ
// ပထမဆုံး ဂဏန်းကို ယူဖို့ ကြာချိန်က အတူတူပါပဲ။
System.out.println(array[0]); // O(1)
}
Linear Time
အချက်အလက်ပမာဏ များလာတာနဲ့အမျှ ကြာချိန်ကလည်း တိုက်ရိုက် အချိုးကျ များလာပါတယ်။ Array က ၁၀ ဆ ကြီးလာရင် ကြာချိန် ၁၀ ဆ ပိုကြာပါမယ်။
public void printAllElements(int[] array) {
// Loop က Array ရဲ့ အရွယ်အစား (N) အကြိမ် အရေအတွက်အတိုင်း အလုပ်လုပ်ပါတယ်။
for (int i = 0; i < array.length; i++) { // O(N)
System.out.println(array[i]);
}
}
Quadratic Time
အချက်အလက် ပမာဏ များလာသည်နှင့် အမျှ ကြာချိန် က နှစ်ထပ်ကိန်း (Square) အချိုးနဲ့ များလာပါတယ်။ များသော အားဖြင့် Loop နှစ်ထပ် (Nested Loop) တွေ မှာ တွေ့ရပါတယ်။
public void printAllPairs(int[] array) {
// အပြင် Loop က N ကြိမ် အလုပ်လုပ်တယ်
for (int i = 0; i < array.length; i++) {
// အတွင်း Loop ကလည်း အပြင် Loop တစ်ခါပတ်တိုင်း N ကြိမ် ထပ်လုပ်တယ်
for (int j = 0; j < array.length; j++) {
System.out.println(array[i] + ", " + array[j]);
}
}
}
// Time complexity: O(N * N) = O(N^2)
Logarithmic Time
အလွန်မြန်ဆန်သည့် Algorithm လို့ ဆိုလို့ရပါတယ်။ အချက်အလက်တွေ များလာပေမယ့် ကြာချိန် က အနည်းငယ်ပဲ တိုးလာပါတယ်။ အဆင့် တစ်ဆင့် လုပ်တိုင်း ကျန်နေသည့် အချက်အလက် တစ်ဝက်ကို ပယ်ဖျက်သွားနိုင်သည့် လုပ်ငန်းစဥ်တွေ ဖြစ်ပါတယ်။ ဥပမာ Binary Search လိုမျိုးပေါ့။
Algorithm မှာ Log ဆိုတာ
ပုံမှန် သင်္ချာမှာ log ဆိုရင် Base 10 သို့မဟုတ် Base e ကို ယူဆပါတယ်။ Computer Science မှာတော့ လို့ ရေးထားခဲ့ရင် Base 2 ()ဖြစ်ပါတယ်။
ဆိုတာ ဘာလဲ ?
ဆိုတာ 1 ရောက်အောင် 2 နဲ့ ဘယ်နှကြိမ်စားနိုင်လဲဆိုတာကို ဖော်ပြတာပါ။
N = 8 ဆိုပါစို့ ။ 8 ကို တစ်ဝက်စီ ပိုင်း ခဲ့ရင် ၃ ခါ ပိုင်းရပါတယ်။ 8 → 4 → 2 → 1 ။ တနည်းပြောရင် 8 = ပါ။ အဲဒီ အဓိပ္ပာယ်က နဲ့ အတူတူပါပဲ။
ဥပမာ Array ထဲမှာ အခန်း အရေအတွက် 1024 ရှိတယ် ဆိုပါစို့။ N = 1024 ပါ။ Algorithm ရဲ့ Big O က ဆိုပါစို့။
ရပါတယ်။ ဒါကြောင့် ဒီ algorithm က အရမ်းမြန်တယ်။ 1024 အခန်းတောင် 10 ကြိမ်ပဲ အလုပ်လုပ်ရပါတယ်။ Time Complexity ကောင်းတယ်လို့ ဆိုရပါမယ်။
public int binarySearch(int[] sortedArray, int target) {
int left = 0;
int right = sortedArray.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (sortedArray[mid] == target) {
return mid;
}
// အဆင့်တစ်ဆင့်တိုင်းမှာ ရှာရမယ့်အပိုင်းကို တစ်ဝက်စီ လျှော့ချပစ်ပါတယ်။
if (sortedArray[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
// Time complexity: O(log N)
Linearithmic Time
ထက် အနည်းငယ် ပိုကြာသော်လည်း ထက် အများကြီး ပိုမြန်ပါတယ်။ အချက်အလက်တွေကို တစ်ဝက်စီ ပိုင်းခြားပြီးမှ ပြန်လည်ပေါင်းစပ်တဲ့ (Divide and Conquer) အယ်ဂိုရီသမ်တွေမှာ အများဆုံး တွေ့ရပါတယ်။ ထိရောက်တဲ့ Sorting Algorithm အများစုရဲ့ Time Complexity ဖြစ်ပါတယ်။ ဥပမာ Merge Sort က အခြေအနေ အားလုံးမှာ ဖြစ်ပါတယ်။ Quick Sort ကတော့ ပျမ်းမျှ (average) ဖြစ်ပေမယ့် worst case မှာ အထိ ဆိုးနိုင်ပါတယ်။
// အသေးစိတ်ကို နောက်ပိုင်း လေ့လာရပါမည်။
public void sortArray(int[] array) {
java.util.Arrays.sort(array);
}
// Time complexity: O(N log N)
Sorting algorithm အများစု၏ average time complexity သည် O(N log N) ဖြစ်သည်။
Exponential Time
အချက်အလက် တစ်ခုတိုးလာတိုင်း ကြာချိန်က ၂ ဆစီ ပွားသွားပါတယ်။ များသောအားဖြင့် Branch တွေ အများကြီးခွဲထွက်သွားတဲ့ Recursive အယ်ဂိုရီသမ်တွေမှာ တွေ့ရပါတယ်။
public int fibonacci(int n) {
if (n <= 1) return n;
// Function တစ်ခါခေါ်တိုင်း နောက်ထပ် Function ၂ ခုကို ပြန်ခွဲထွက်သွားပါတယ်
return fibonacci(n - 1) + fibonacci(n - 2);
}
// Time complexity: O(2^N)
Space Complexity (မှတ်ဉာဏ် အသုံးပြုမှု)
Space Complexity ဆိုတာ Algorithm မှာ အလုပ်လုပ်ဖို့အတွက် Memory ဘယ်လောက် လိုအပ်လဲ ဆိုတာကို တိုင်းတာတာပါ။ Data (Input) ယူထားတဲ့ နေရာကိုတော့ ထည့်မတွက်ပါဘူး။ Data အသစ်ဖန်တီးတာ၊ Array အသစ် ဆောက်တာတွေကိုပဲ ထည့်တွက်ပါတယ်။
Constant Space
Input Data ဘယ်လောက်များများ၊ memory အသစ်မလိုပါဘူး။
public int sumArray(int[] array) {
int sum = 0; // Integer variable တစ်ခုစာပဲ နေရာယူပါတယ်။ (O(1) space)
for (int i = 0; i < array.length; i++) {
sum += array[i];
}
return sum;
}
// Space Complexity: O(1)
Linear Space
Input Data ပမာဏနဲ့ အချိုးကျပြီး Memory လိုအပ်ပါတယ်။
public int[] copyArray(int[] array) {
// မူလ Array ရဲ့ အရွယ်အစား N နဲ့တူညီတဲ့ Array အသစ်တစ်ခုကို တည်ဆောက်ပါတယ်။
int[] newArray = new int[array.length]; // O(N) space
for (int i = 0; i < array.length; i++) {
newArray[i] = array[i];
}
return newArray;
}
// Space Complexity: O(N)
- Quadratic Space
Input Data ကို မူတည်ပြီး 2D Array (သို့) Matrix တွေ တည်ဆောက်တဲ့အခါ တွေ့ရပါတယ်။
public int[][] createMatrix(int n) {
// N x N အရွယ်အစားရှိတဲ့ Matrix အသစ် တည်ဆောက်တာ ဖြစ်ပါတယ်။
int[][] matrix = new int[n][n]; // O(N * N) space
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
matrix[i][j] = i + j;
}
}
return matrix;
}
// Space Complexity: O(N^2)
Time Complexity နှင့် Space Complexity တို့၏ Trade-Off
လက်တွေ့မှာ အကောင်းဆုံး နဲ့ memory အနည်းဆုံး နှစ်ခု လုံး ရဖို့ မလွယ်ကူပါဘူး။ တစ်ခုကို လိုချင်လျှင် တစ်ခုကို အလျော့ပေးရပါမယ်။ Trade Off လုပ်ရတာပေါ့။
- Time Complexity ကောင်းချင်လျှင် Space Complexity အားနည်းပါတယ်။ ဥပမာ Caching လိုမျိုး ပြန်တွက်စရာ မလိုပဲ သိမ်းထားသည့် ကိစ္စတွေမှာ Time Complexity ကောင်းပေမယ့် Space Complexity မကောင်းပါဘူး။
- Space Complexity ကောင်းချင်လျှင် Time Complexity အားနည်းပါတယ်။ တွက်ချက်မှု တွေကို ကြိုတင်သိမ်းထားမှု မရှိပဲ လိုမှ တွက်သလိုမျိုးပေါ့။
ဥပမာ - Array တစ်ခုတည်းမှာ နံပါတ်တွေ ထပ်နေတာ (Duplicates) ရှိမရှိ စစ်ဆေးခြင်း
နည်းလမ်း ၁။ Nested Loops သုံးခြင်း (ကြာချိန် နှေးသွားမည်၊ မှတ်ဉာဏ် သက်သာမည်)
public boolean hasDuplicatesSlow(int[] array) {
for (int i = 0; i < array.length; i++) {
for (int j = i + 1; j < array.length; j++) {
if (array[i] == array[j]) return true;
}
}
return false;
}
// Time: O(N^2) - ဂဏန်းတစ်လုံးကို ကျန်တဲ့ဂဏန်းတိုင်းနဲ့ လိုက်စစ်ရလို့ ကြာပါတယ်။
// Space: O(1) - Data အသစ်/Array အသစ် ထပ်မဆောက်လို့ မှတ်ဉာဏ် လုံးဝသက်သာပါတယ်။
နည်းလမ်း ၂။ HashSet သုံးခြင်း (Hash Table အကြောင်းကို နောက်ပိုင်း အခန်းတွေမှာ အသေးစိတ် တွေ့ရပါမည်)
public boolean hasDuplicatesFast(int[] array) {
HashSet<Integer> seen = new HashSet<>(); // Memory အသစ် ယူလိုက်ပါပြီ!
for (int num : array) {
if (seen.contains(num)) return true; // ရှာရတာ O(1) ဖြစ်လို့ မြန်ပါတယ်
seen.add(num);
}
return false;
}
// Time: O(N) - Array ကို တစ်ခေါက်ပဲ ပတ်စရာလိုတဲ့အတွက် မြန်ပါတယ်။
// Space: O(N) - ဂဏန်းတွေကို HashSet ထဲအသစ်ပြန်ထည့်ရလို့ Memory (N) စာ ပိုယူသွားပါတယ်။
Production မှာ ဘာကြောင့် အန္တရာယ်ရှိသလဲ
algorithm ဟာ data နည်းတဲ့ အချိန် (test data) မှာ ပြဿနာ မတက်ပါဘူး။ ဒါပေမယ့် production မှာ data ကြီးလာတဲ့အခါ အလွန် ဆိုးရွားသွားနိုင်ပါတယ်။
- ဆိုရင် — အဆင်ပြေပါသေးတယ်။
- ဆိုရင် — စတင် နှေးလာပါပြီ။
- ဆိုရင် — server လုံးဝ ရပ်သွား (timeout) နိုင်ပါတယ်။
တကယ့် ဥပမာ — user 1,000 ယောက်ပဲ ရှိစဉ်က ကောင်းနေတဲ့ feature တစ်ခုဟာ user သိန်းနဲ့ချီ များလာတဲ့အခါ ရုတ်တရက် နှေးကွေးသွားတတ်ပါတယ်။ ဒါကြောင့် data ကြီးနိုင်တဲ့ နေရာတွေမှာ ကို ရှောင်သင့်ပါတယ်။
Real-World ဥပမာများ
Time Complexity ဟာ စာသင်ခန်း သီအိုရီ မဟုတ်ပါဘူး။ နေ့စဉ် development မှာ ဒီလို တွေ့ရပါတယ်။
- Database records: record သန်းနဲ့ချီ ထဲက item တစ်ခုကို index မပါဘဲ ရှာရင် ဖြစ်ပြီး နှေးပါတယ်။ index (B-Tree) ပါရင် နဲ့ မြန်ပါတယ်။
- API response list: API ကပြန်လာတဲ့ list ထဲမှာ item တစ်ခုစီကို loop နှစ်ထပ်နဲ့ နှိုင်းယှဉ်ရင် ဖြစ်ပြီး response နှေးသွားပါတယ်။
- Transaction list: ဘဏ် transaction list ထဲက duplicate ရှာတာ၊ စုစုပေါင်း ပေါင်းတာတွေဟာ list အရွယ်အစား ပေါ် တိုက်ရိုက် မူတည်ပါတယ်။
Solution နှစ်ခုကို ဘယ်လို နှိုင်းယှဉ်မလဲ
Algorithm နှစ်ခု ရှိရင် ဘယ်ဟာ ပိုကောင်းလဲ ဆုံးဖြတ်ဖို့ အောက်ပါ အဆင့်တွေနဲ့ နှိုင်းယှဉ်ပါ။
- Time Complexity နှိုင်းယှဉ်ပါ။ ဥပမာ က ထက် ပိုကောင်းပါတယ်။
- Space Complexity ကို ကြည့်ပါ။ Time တူရင် memory နည်းတဲ့ဟာ ပိုကောင်းပါတယ်။
- Data အရွယ်အစား () ကို စဉ်းစားပါ။ သေးရင် ရိုးရှင်းတဲ့ က လုံလောက်ပါတယ်။ ကြီးရင် သို့ လိုပါတယ်။
- Trade-off ကို ဆုံးဖြတ်ပါ။ အပေါ်က duplicate ဥပမာမှာ Nested Loop က time / space ၊ HashSet က time / space ။ Data ကြီးရင် HashSet ( time) ကို ရွေးတာ ပိုသင့်တော်ပါတယ်။
အကျဉ်းချုပ်: "ပိုကောင်းတဲ့ solution" ဆိုတာ အမြဲ Big O နည်းတာ မဟုတ်ပါဘူး။ Data အရွယ်အစား နဲ့ memory ကန့်သတ်ချက် အပေါ်မူတည်ပြီး ဆုံးဖြတ်ရပါတယ်။
အခု ဆိုရင် အနည်းငယ် သဘောပေါက်ပြီလို့ ထင်ပါမယ်။ နောက်ပိုင်း အခန်းတွေ မှာ algorithm တိုင်း ကို Time Complexity နဲ့ Space Complexity ကို ဖော်ပြပေးသွားပါမယ်။ တချို့ sorting တွေမှာ တော့ အသေးစိတ် ပြန်လည် ရှင်းပြပါမယ်။ ထို့မှသာ နားလည် လွယ်ပါလိမ့်မယ်။